About two years ago I wrote about a category-theoretic treatment of collaborative text editing. That post is unique in the history of Bosker Blog in having been cited – twice so far that I know of – in the academic literature; so it’s a little embarrassing for me to have to explain that it is almost entirely wrong. The good news is that the core idea can be rescued, and the corrected story is quite interesting. Other writers on this subject seem to have made at least some of the same mistakes I did, so I hope this will be useful to at least a few other people too.
I was considering the problem of collaborative text editing, where several people separately and simultaneously are editing the same document and communicating their changes asynchronously to each other:
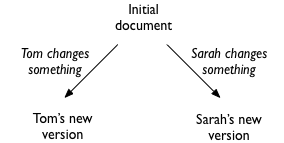
Each editor must then incorporate the other’s change into their version of the document, which must be done in such a way that they both end up with the same thing:

The hard case is where Tom and Sarah’s changes overlap: say they have both changed the same word to something different. In the example I used, the document read “The cat sat on the mat”, and they both select the word cat:

Then Tom types ‘dog’, and Sarah types ‘chicken’. This appears to be unresolvable if we require our documents to be linear – but we can achieve a canonical resolution if we permit non-linear documents:

In general the resolved document contains all the characters that neither editor changed, together with all the characters inserted by Tom and all the characters inserted by Sarah, ordered in the minimal way that is consistent with both documents.
So far so good. Now it starts to go wrong. There are two fundamental problems: pushouts imply pathological documents, and deletions lead to disaster. In turn:
Pushouts imply pathological documents
I said this resolution was a pushout in a category of edits. That is not true as I stated it, and moreover I think the examples show that we don’t want it to be true.
My previous example will not do here, since “dog” and “chicken” have no letters in common. Let us suppose, then, that instead of dog and chicken we have badger and donkey:

Let us recall what it means for the resolution to be a pushout. Start with a document that we shall call A, and suppose that, simultaneously:
- Tom makes an edit, call it f, resulting in the document B;
- Sarah makes an edit, call it g, resulting in the document C.
These edits are propagated: both parties run the resolution algorithm, and then Tom applies Sarah’s edit and Sarah applies Tom’s. Let’s label the resolved version of f as f’, the resolved version of g as g’, and the resulting document P.

[…]
Now, the properties of the pushout require that, given any resolution of the two edits (“The donkey sat…” and “The badger sat…”) there must be a unique edit from the pushout to this other resolution. One possible resolution would be to insert letters into the name of the animal to make “badonkeyger”:
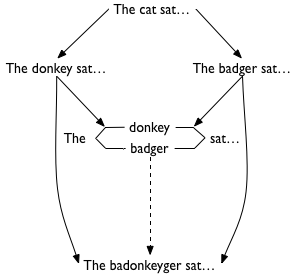
In other words, the properties of the pushout require us to admit an edit that takes the parallel donkey/badger and flattens it out, identifying the two d’s.
This seems perverse. It certainly is not in line with my intuition about what sorts of edits ought to be permissible. But it gets worse! By admitting these strange edits that merge letters from parallel tracks, we have opened the door to yet stranger things such as cyclic documents. Consider the following pair of edits that merge two parallel tracks. The bold pink d in badonkeydonkger indicates the image of the ‘d’ in badger: it could have been merged with either of the two d’s in donkeydonk. Resolving this pair of edits will necessarily create a cyclic document.

Samuel Mimram and Cinzia Di Giusto’s article A Categorical Theory of Patches – rather like my earlier On Editing Text – develops a theory where edits are resolved as pushouts. Unlike me, however, they recognised this issue, which they deal with by admitting cyclic documents into their theory. I shall take the alternative approach of arguing that, on the contrary, these examples show that pushouts do not correctly model edit resolution.
It’s okay that our resolutions are not pushouts, because they still have the property we really wanted in the first place: that edits can be resolved in any order and give the same answer. (And it’s good that they’re not, because if they were we would have to admit circularities etc.)
Deletions lead to disaster
The second problem is worse, because we get different answers depending on what order we process the edits. To resolve it we’ll have to change the way we represent deletions.
We’ll start with the document “ABC” and consider three different edits of this document:
- Insert v and w to get “AvBwC”;
- Insert x and y to get “AxByC”;
- Delete the B to get “AC”.
Now, combining (1) and (2) gives:
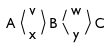
And combining that with (3) gives:

On the other hand, if we resolved these edits in a different order then we get a different answer. Combining (1) and (3) gives “AvwC”, then combining that with (2) gives:
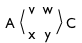
So this resolution procedure is not order-independent, which is very bad. In particular it cannot be a pushout, which I believe shows that Mimram and Di Giusto’s Theorem 20 is false.
Avoiding deletions using tombstones
We can avoid this problem by not allowing characters to be deleted. When a user deletes a character, rather than removing it from the internal representation of the document, replace it with a tombstone marking where the character used to be.
We don’t need to keep these tombstones around for ever, I don’t think. Once we’re sure that an edit has been incorporated by all clients, there is no harm in discarding the tombstones it produced.
An object of the category – a document – is a triple (A, ≤, s) where (A, ≤) is the poset of positions and s: A → Σ assigns a symbol to each position.
A morphism f: A→B is a function such that for all x, y in A:
- x ≤ y ⇔ f(x) ≤ f(y)
- Either s(f(x)) = s(x) or s(f(x)) is a tombstone.
The resolution R of f: A→B and g: A→C has positions A + (B-f[A]) + (C-g[A]). Note that A + (B-f[A]) is isomorphic to B, and A + (C-g[A]) is isomorphic to C. The order of positions is inherited from B and C:
- If b ≤ b’ in B then b ≤ b’ in R
- If c ≤ c’ in C then c ≤ c’ in R
- b ≤ c, for b∈B and c∈C, if there is some a∈A such that b ≤ f(a) in B and g(a) ≤ c in C
- c ≤ b, for b∈B and c∈C, if there is some a∈A such that c ≤ g(a) in C and f(a) ≤ b in B
The assignment of characters to positions is:
- sR(b) = sB(b) for b∈B,
- sR(c) = sC(c) for c∈C,
- sR(a) is a tombstone if either sB(f(a)) or sC(g(a)) is; otherwise sR(a) = sB(f(a)) = sC(g(a)).
What about the connection to the exception monad?
As I understand the situation at the moment, that doesn’t work. Constructing the category of edits in that way seems to rely on having real deletions – which we’ve seen we can’t have.


 that has n dials and k numbers on each dial. Let m(n, k) be the minimum number of turns that always suffice to open the lock from any starting position, where a turn consists of rotating any number of adjacent rings by one place.
that has n dials and k numbers on each dial. Let m(n, k) be the minimum number of turns that always suffice to open the lock from any starting position, where a turn consists of rotating any number of adjacent rings by one place.
