
You know the Fibonacci numbers:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, …
Each number is the sum of the previous two. Let’s say the zeroth Fibonacci number is zero, so:
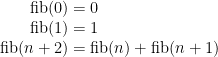
And let’s say you want to write some code to compute this function. How would you do it? Perhaps something like this? (Python code)
def fib_rec(n): assert n >= 0 if n < 2: return n return fib_rec(n-2) + fib_rec(n-1)
This is a pretty popular algorithm, which can be found in dozens of places online. It is also a strong candidate for the title of Worst Algorithm in the World. It’s not just bad in the way that Bubble sort is a bad sorting algorithm; it’s bad in the way that Bogosort is a bad sorting algorithm.
Why so bad? Well, mainly it is quite astonishingly slow. Computing fib_rec(40) takes about a minute and a half, on my computer. To see why it’s so slow, let’s calculate how many calls are made to the fib_rec routine. If we write 
fib_rec(n), then:
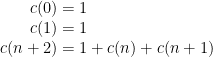
So 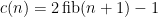
fib_rec takes time O(fib(n)).
So computing fib_rec(40) involves c(40) = 331,160,281 calls to the fib_rec routine, which is pretty crazy considering it’s only called with 40 different arguments. An obvious idea for improvement is to check whether it’s being called with an argument that we’ve seen before, and just return the result we got last time.
cached_results = {}
def fib_improved(n):
assert n >= 0
if n < 2: return n
if n not in cached_results:
cached_results[n] = fib_improved(n-2) + fib_improved(n-1)
return cached_results[n]
That’s a huge improvement, and we can compute fib_improved(40) in a fraction of a millisecond, which is much better than a minute and a half. What about larger values?
>>> fib_improved(1000) 43466557686937456435688527675040625802564660517371780402481729089536555417949051890403879840079255169295922593080322634775209689623239873322471161642996440906533187938298969649928516003704476137795166849228875L
That looks good, and it’s still apparently instant. How about 10,000?
>>> fib_improved(10000) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 6, in fib_improved File "<stdin>", line 6, in fib_improved [...] File "<stdin>", line 6, in fib_improved RuntimeError: maximum recursion depth exceeded
Oh dear! We’ve blown the stack. You could blame Python here for having a hard (if configurable) limit on stack size, but that’s not the real point. The problem here is that this algorithm creates n stack frames when you call fib_improved(n), so it uses at least O(n) space.
(Actually it uses O(n2) space — later we’ll get into why that is. Thanks to CoderKyd on reddit for pointing that out.)
It’s easy enough to write a version that only uses constant space — well, not really: but it only uses twice as much space as we need for the end result, so it’s within a small constant factor of optimal — as long as we’re willing to forgo recursion:
def fib_iter(n):
assert n >= 0
i, fib_i, fib_i_minus_one = 0, 0, 1
while i < n:
i = i + 1
fib_i, fib_i_minus_one = fib_i_minus_one + fib_i, fib_i
return fib_i
This is much better. We can compute fib_iter(100,000) in less than a second (on my computer, again), and fib_iter(1,000,000) in about 80 seconds. Asymptotically, this algorithm takes O(n2) time to compute fib(n).
(Maybe you think it should be O(n) time, because the loop runs for n iterations. But the numbers we’re adding are getting bigger exponentially, and you can’t add two arbitrarily-large numbers in constant time. If you think that sounds a bit theoretical, you might enjoy the post where Peteris Krumins measures the running time of fib_iter, and explains why it’s quadratic rather than linear.)
That’s not the end of the story. Since the Fibonacci numbers are defined by a linear recurrence, we can express the recurrence as a matrix, and it’s easy to verify that
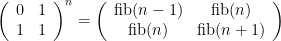
Since we can get from 
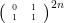
def bits(n):
"""Represent an integer as an array of binary digits.
"""
bits = []
while n > 0:
n, bit = divmod(n, 2)
bits.append(bit)
bits.reverse()
return bits
def fib_mat(n):
assert n >= 0
a, b, c = 1, 0, 1
for bit in bits(n):
a, b, c = a*a + b*b, a*b + b*c, b*b + c*c
if bit: a, b, c = b, c, b+c
return b
This is certainly much faster in practice. We can compute fib_mat(1,000,000) in less than a second and a half. The asymptotic complexity depends on the multiplication algorithm used. If it’s conventional long multiplication then multiplying two k-bit numbers takes time O(k2), in which case this algorithm is actually still quadratic! I believe Python uses the Karatsuba algorithm, which makes it about O(n1.6) in Python.
While we’re writing code, let’s improve the constant factor. Each step of fib_mat uses six multiplications, but we can halve that just by observing that c can always be computed as a+b and rearranging things a little:
def fib_fast(n):
assert n >= 0
a, b, c = 1, 0, 1
for bit in bits(n):
if bit: a, b = (a+c)*b, b*b + c*c
else: a, b = a*a + b*b, (a+c)*b
c = a + b
return b
And this does indeed run about twice as fast. Further improvement is possible, but I think the point has been made so let’s leave it there. If you want to see a super-efficient version, have a look at the algorithm in GMP.
Another good article on the subject: David Eppstein’s lecture notes, which cover similar ground to this.
If you’re thinking “This is silly! You can just compute Fibonacci numbers using the closed-form expression.” then you’ll probably enjoy the follow-up article on computing Fibonacci numbers using Binet’s formula.
Are you wondering what this has to do with mazes? We’ll get to that eventually, I hope…

What do you think of an algorithm that uses the Closed-form expression of Fibonacci numbers? Obviously you will have precision problems for large values of n, but if your exponential function is logarithmic time, the Fib function should be as well.
Hi Lionel. I’d love to see an algorithm using the closed-form expression. (One that gives an exact answer, I mean! Obviously it would be easy to do using floating-point arithmetic, but that would only give an approximate answer.)
It would only be logarithmic time in the way that
fib_matis, I think. In other words, it would use a logarithmic number of multiplications, but the numbers being multiplied would get bigger exponentially in n, which would counteract that. (To get an exact answer for larger n would require the calculation to be done with more bits of precision, I mean.)One way to reach an exact result is using arbitrary precision floating point arithmetics.
Another way to perform the calulations in the ring Z[sqrt(5)], which means calculating with pairs of integers. (see HN the news comment where someone provided the formulas: http://news.ycombinator.com/item?id=2538724 )
Working in Z[sqrt(5)] is a very neat idea! Thanks for drawing my attention to that.
You should specify that the naive implementation is the worst algorithm in the world for some languages. For example a Haskell implementation of this algorithm doesn’t incurr in the problems you are listing.
Hi Fransisco. I’m not sure I understand what you mean. The Haskell function
fib 0 = 1fib 1 = 1
fib (n+2) = fib n + fib (n+1)
is just as bad as the Python equivalent, I believe, and for the same reasons. I’ve just tried it, and it can’t compute even
fib 100.Did you mean something different?
It should be as good as fib_improved in python. Haskell should not be evaluating twice the same expression. But I could be wrong.
Ah, I see. You are wrong, I’m afraid. Try it!
Good review of this particular problem:
http://cgi.cse.unsw.edu.au/~dons/blog/2007/11/29#smoking
To really get Haskell performance out you should use ghc compiler with optimization:
ghc -O2 fib.hs -o fib -no-recomp
Gosh. I’m not sure how I feel about that. There is something a little disturbing about putting so much optimisation effort into such a slow algorithm.
It’s impressive that GHC can do so well with such a lousy algorithm — but it’s still never going to be able to compute fib(100) before the heat death of the universe.
This is a much better Haskell solution:
fibs = 0 : 1 : zipWith (+) fibs (tail fibs)
Then you just ‘take’ as many as you need.
— Get the 10000th fib number:
last $ take 10000 fibs
My point was that the naive implementation is not the worst algorithm ever. For some languages is not bad, it’s clear and it’s fast enough.
Francisco you are probably assuming automagic memoization.
See
FYI – http://www.haskell.org/haskellwiki/Memoization
with naive Fib being the ‘canonical’ example.
Well… there is an explicit functional form for the Fibonacci numbers. Why not use that instead of recursion?
Because the closed form cannot be calculated exactly on a computer. It involves calculations using an irrational number.
It can be calculated, using arbitrary precision floating point arithmetics such as the GMP library. However, the question is whether this would be any faster than the other algorithms.
let fibs = 0 : 1 : zipWith (+) fibs (tail fibs) in Haskell works fine for pretty high into the sequence, and is to me much prettier than anything that appears in this post.
Yes, that’s a beautiful bit of code! Very Haskellish.
The algorithm is essentially the one I called
fib_iter, isn’t it? Though I suspect it uses O(n) memory, so maybe it’s really more similar tofib_improved.Don’t underestimate the Haskell compiler. It is very possible that those (simple?) kinds of optimizations are already happening.
Oh, I would never underestimate the Haskell compiler! That’s why I said “I suspect” rather than “I am sure”.
I just tried this simple program, compiled with ghc -O2
import System (getArgs)fibs = 0 : 1 : zipWith (+) fibs (tail fibs)
main = do
args <- getArgs
let n = read $ head args
print $ fibs !! n
I tried it with
./fibs 1000000, and had to kill the process after it ate two GB, so I think it really is using all the memory you’d naively expect it to.Careful there. You make the mistake several times of conflating n-bit numbers with size n numbers. A number n has ~log(n) bits in it. Addition is absolutely an O(log(n)) operation. Same with multiplication.
The algorithm you claim is O(n^2) is actually no more than O(n*log(n)). The “fast” version with matrices is not quadratic at all: the multiplication is O(log(n)) and so is the matrix decomposition, giving O(log(n)^2) time.
Hi Alex. I don’t think I’ve made that particular mistake, though I obviously haven’t explained myself very clearly if you think I did! Remember that n is the input value: the intermediate values used in the calculations are tending towards fib(n), which has O(n) bits.
I really liked Peteris Krumins’ explanation of why
fib_iteris quadratic. He actually measures the running time and observes quadratic behaviour, so I don’t think it can be pinned on a mistaken calculation.Fast implementations in Haskell can be found at http://www.haskell.org/haskellwiki/The_Fibonacci_sequence#Using_2x2_matrices , kind of interesting.
We don’t know this thing before reading this article.Very interesting and hidden truth about the program..
And what’s wrong with simple http://pastebin.com/Xg9YYGbP ?
Nothing wrong with that at all! Roughly it’s an iterative implementation of
fib_improved, isn’t it? The main disadvantage of this, compared to the better algorithms, is that it uses a lot of memory.Fair enough, but if you use my improved one: http://pastebin.com/4Eq061xe it would use a lot of memory though, is it?
Cute, Harrie! I think that’s the same as the one I called
fib_iter, but using an array with two elements rather than two variables.This material is covered in lecture 3 of MIT’s class on algorithm theory, which is on-line at their Open Course-Ware (OCW) site.
http://tinyurl.com/2cg4yo9
Good analysis but I really dislike the title.
The only places where I’ve seen the recursive fibonacci is being used as a mathematical definition or as an example to explain the dangers in recursive algorithms.
Never would consider it a “real” algorithm.
I agree it’s not a “real” algorithm, but I don’t think everyone realises that!
Unfortunately, this algorithm was presented with a straight face in many of my undergrad CS courses! It was the de facto implementation of F[n] and was never elaborated upon. *sigh*
The use of O(log(n)) only seems better than the O(n) of simply adding the numbers sequentially if one forgets that arbitrary length multiplication (performed on the order of log2(n) times) is itself a O(n) operation giving us O(nlog(n)) for the matrix method. This added complexity doesn’t cease to exist just because the language hides it.
I forgot to post my simple (truly) O(n) algorith.
def fib(n):
assert n >= 0
a = 0
b = 1
i = 2
while i < n:
c = a+b
a,b,i = b,c,i+1
return b
Exactly. I was looking for someone with this approach. This is relatively easy, linear time, and cannot be significantly improved.
Excellent.
Which language are you using?
With recursion
– write algorithm with recursion
– make sure you have a trap out
– check performance at likely max number of recursive calls
– if that is unacceptable you rewrite non recursively using recursive algorithm to compare results
and as “Some Dude” post – this is trivial to re-write non-recursively
Pingback: Fibonacci number generation in Java « mytechstuff
Pingback: Calculating the Fibonacci Numbers | Irreal
This algorithm is usually used to introduce the concept of recursion. Of course, an easier and more obvious way to write it is using a loop. That’s not the problem of education though, as any adequate programmer will get to this conclusion without any advice.
Still, I wonder how many times have you seen Fibonacci numbers computed in the production code? Is it worth optimizing the thing which is never really used for anything useful other than introducing the concept of recursion?
I don’t know any practical use for computing the actual Fibonacci numbers, but the reason I started to think about this is because I wanted to compute the function
m(0) = 0
m(1) = 1
m(n+2) = 4m(n+1) – m(n)
(This computes the number of possible mazes on a 2×n grid. If you’ve looked at the maze posts here, you’ll see the relevance of that.)
When it comes to algorithms, one linear recurrence is much like another, so I wrote about the Fibonacci numbers because they’re friendly and familiar – but this was very much inspired by a real problem I wanted to solve.
No offense. I totally see the point of the post. I just don’t like the title. Naming something that’s meant as an example the worst thing ever just doesn’t seem right.
After all, we’ve all learned bubble sort. No matter how impractical this algorithm is, it’s arguably the easiest one to understand. So is the case with Fibonacci numbers: it’s easier to explain recursion using them (or using factorial, doesn’t matter) than using a wave-algorithm for pathfinding or something similar.
An interesting anecdote — to play with this idea, I implemented the iterative algorithm on an HP 12-C calculator in RPN (I happened to already have this handy just from playing with RPN). I implemented the recursive algorithm in bc, and executed it on an 3ghz Intel i7.
I started them both at the same time. The 200khz HP 12-C was over four times faster than the recursive version on a 3ghz intel.
It’s a fine algorithm: it just needs memoizing!
Using the
memoizeddecorator from the Python Decorator Library:@memoized def fib(n): assert n >= 0 if n < 2: return n return fib(n-2) + fib(n-1) >>> import timeit >>> timeit.timeit("fib(100)", "from __main__ import fib") 0.57807588577270508 #microsecondsThanks for the comment, Gareth. I agree this is a lovely example of the power of memoization.
I thought about writing
fib_improvedusing a decorator rather than memoizing it by hand. I decided not to, for two reasons:1. I thought it would be more confusing for readers who didn’t know Python, because Python’s decorator syntax is rather idiosyncratic.
2. The result is not as good, because each recursive call uses two stack frames rather than one, so you hit the limit much sooner: even
fibonacci(500)fails with the default recursion limit.Interesting post.
One thing, though: if I’m not mistaken, Python probably doesn’t use Karatsuba for arbitrary multiplication. Karatsuba has really, really bad constants, and is typically reserved for only very large numbers. It probably will transition to Karatsuba as the numbers become large enough, but especially for small numbers, it is not the case that this is the best algorithm available.
That’s a relatively minor point though.
I’m pretty sure bogosort has upper bounds of O(infinity) since it is a random algorithm. That would make it worse.
True.
I still think the comparison with bogosort is reasonably fair, because the running time of bogosort – measured in number of swaps, assuming the Fisher-Yates algorithm is used to implement the shuffle – has a geometric distribution with a mean of n·n!, so the expected run-time is of the same approximate order of badness as the c(n) estimate for
fib_rec.Pingback: State of Technology -#9 « Dr Data's Blog
Pingback: Fibonacci recursivo ou iterativo? - Márcio Francisco Dutra e Campos
Or, if you solve the linear equation for fib(n), you get:
fib(n) = (((1+sqrt(5))/2)^n-((1-sqrt(5))/2)^n)/sqrt(5)
Assuming that exponentiation is implemented with logs, it’s O(1).
Computing powers, even if you do it using logarithms, is definitely not a constant-time operation. See http://en.wikipedia.org/wiki/Computational_complexity_of_mathematical_operations for example.
Of course you can write a program that will work for small values of n using floating-point arithmetic, but it will start to give wrong answers pretty quickly as n gets larger.
I’m pretty sure the worst algorithm in the world is hidden somewhere in the source for Lotus Notes.
What about the Ackermann funtion?
Dynamic programming would save you from recalculating the value in the recurrence.
What about parallel computing? Any algorithms running faster on multicore machines?
For a slightly more efficient recursive algorithm how about:
def f(n):
if n 0), 0)
else:
a,b=f(n-1)
return (a+b,a)
It’s a bit pointless since you’ll run out of stack space pretty quickly, but it feels good to write something “better than textbook” ;).
JB
A good article, but this made me twitch:
“what use is a model whose assumptions hide a physical impossibility?”
It’s like a civil engineer sneering at a physicist. Engineering is a product of science, and you should have a little more respect for the scientist’s tools.
Hmm, interesting. That isn’t how I meant it to sound, but I can see why you read it that way.
I should probably delete that whole paragraph. There is a serious and important point to be made, I believe; but I don’t think I’ve succeeded in making it here, and it doesn’t really belong in the middle of an essay about computing Fibonacci numbers.
Thanks for the comment.
(Added later: I did delete the paragraph, which might make this exchange hard to understand if you’re reading it now.)
Pingback: Computing Fibonacci numbers using Binet’s formula « Bosker Blog
That is why I program in Mathematica (disclaimer: I am an engineer and program for mostly modeling purposes and multivariate optimization), but it is surprisingly versatile. True, some languages handle some things a bit more elegantly, but functional, procedural and OO programming in it is easy and all can be incorporated simultaneously.
In addition, I love the ability to have a Java and Python plugin. Good article though, I learned something :)
I read the entire article thinking, “why not just use the closed-form algorithm?” and then I got to the last sentence :D
Pingback: The worst algorithm in the world? – aldemir.net
I enjoy reading your Algorithm Blog, and would like to respectfully ask a question.
I was wondering if you had any thoughts on buying mathematical algorithms vs. programming them yourself? Especially for complicated mathematical subroutines, is it cost effective to subscribe to an algorithm library (like http://www.nag.com) for about $3000 per year, or let your programmers do all the work?
Have you ever offered an opinion on this subject?
about this, I would sincerely appreciate a link. If not, I would appreciate any informed opinions.
Thanks, Steve
Thanks, Steve Chastain
Hi Steve. What an interesting question. I would have thought it depends rather a lot on what algorithms you need. Algorithms that are used a lot usually have at least an acceptably-good free implementation available somewhere, so I guess there is a third option: use an open source library. But between the three options I think the decision has to be made on a case-by-case basis. The relevant factors certainly include:
The same considerations as when deciding “build or buy” for any software, I suppose. Do you have a particular problem or algorithm in mind?
Robin,
Great answer thanks! I was interested it you, or any of your readers, had any specific experience with algorithm libraries? I’m wondering about the quality of the algorithms and how helpful the Tech Support people are in making it work in your program? If anyone has any experience (like Numerical Algorithm Group), I’d love hear any opinions.
Thanks again, Steve
I never tried to code a Fibonacci function.
But it took me 1 minute to realize it could not be done using:
def fib_rec(n):
assert n >= 0
if n < 2: return n
return fib_rec(n-2) + fib_rec(n-1)
This is probably the most inefficient algorithm ever. Even your cached one is super inefficient.
In 5 minutes I have done this C# function that gives me all results in milliseconds:
long fib(int numb)
{
if (numb == 0)
return 0;
if (numb == 1)
return 1;
long a = 0;
long b = 1;
long c = 0;
for (int i = 2; i <= numb; i++)
{
c = a + b;
a = b;
b = c;
}
return c;
}
in python, (without the encoding and decoding strucgures) this gives the nth number (im on the phone, you can do 1 & 2 yourself lol)
a,b=0,1
import time
def fibn(n):
time.clock()
for i in range(int(n/2)):
a,b=a+b,a+b
return time.clock(), len(b)
for a simple iteration algorithm,
it can do up to n=100,000 in under a second, not too shabby for 2 minutes of work
Pingback: Just occasionally, one would be quite lost without recursion | Bosker Blog
Dear Florian Philipp,
I know this is not faster way to calculate Fibonacci series but for the better understanding i write like that its easy to understand for beginners.
Pingback: The Fibonacci sequence and linear algebra - Science